

Framework casually mentioned they were testing a mini-rack AI cluster in their Framework Desktop presentation back in March.
Imagine my surprise when Nirav Patel, Framework’s founder and CEO, was at Open Sauce a couple weeks ago, and wanted to talk! He said they had seen my Project Mini Rack posts earlier this year and thought it was the perfect application to try out their new AMD Ryzen AI Max+ 395-powered Mainboard, as it’s mini ITX dimensions fit inside a 10″ rack.
Framework sent over four pre-release Mainboards (along with four of their new Power Supplies, and Noctua CPU Fan kits), and also worked with DeskPi to get my hands on a new 2U Mini ITX tray for the Framework Desktop—which I installed in the black RackMate T1 mini rack you see at the top of this post.
I have a video going over everything, including cluster setup, single node and cluster AI inference performance, and my conversation with Nirav—you can watch that below:
The most prescient thing Nirav mentioned was this:
It is obviously like very very early days, in terms of like, open source AI clustering…
I spent equal time running benchmarks as I did getting the benchmarks to run. I tested (and automated clustered setup for) Exo, llama.cpp RPC, and distributed-llama.
In fact, through all that work, I built a new project Beowulf AI Cluster, a set of Ansible automation playbooks to deploy different open source AI clustering tools on beowulf clusters, with CPU, GPU, and mixed inference options.
Hardware
This post won’t go into detail on the Framework Desktop or the Mainboard that powers it. Either watch the video or check out someone else’s overview for that.

Framework shipped over four sets of Mainboard, PSU, and Noctua CPU Fan, along with 1TB WD NVMe SSDs. I assembled everything together into a black DeskPi 8U mini rack.
The boards are more akin to SBCs than traditional socketed-CPU-and-RAM desktop boards, though, in that they have a soldered-down APU (includes CPU, NPU, and iGPU) and RAM.
Supposedly they have to be soldered down (instead of using something like CAMM) to keep the memory timings in check for the best performance for things like AI workloads.
Basic Clustering
After getting everything put together, I ran a gauntlet of tests. I’ve documented everything in various issues across my GitHub repositories:
But I’ll hit a few of the highlights in this post, if you don’t want to dig too far into the weeds.

First, from an environmental level, the noise output is very low and pleasant, at least if you opt for the Noctua CPU fan kits Framework provides. The Mainboard includes a pre-installed heatsink using phase-change thermal interface material (for more effective heat transfer off the bare APU die), and the fans will even spin down at idle.
For individual nodes, sleep power draw is around 2W, idle power draw 11W, and full-bore, it’ll pull around 150W. It goes into a higher turbo boost momentarily but will settle in around 145-155W for extended maxed-out benchmarks, at least on the CPU side. All my measurements were done at the wall and while running Fedora 42 (or in some cases, Rawhide, the in-development version of Fedora).
For networking, I expected more out of the Thunderbolt / USB4 ports, but could only get 10 Gbps. The built-in NICs are 5 Gbps and I had no problems reaching that speed over Ethernet. I’m hopeful drivers or Linux tweaks would be able to bump Thunderbolt node-to-node connectivity at least over 15 or 20 Gbps.
In terms of general compute, just one of these systems (not clustered) could compile the Linux kernel (running pts/build-linux-kernel) in less than a minute:
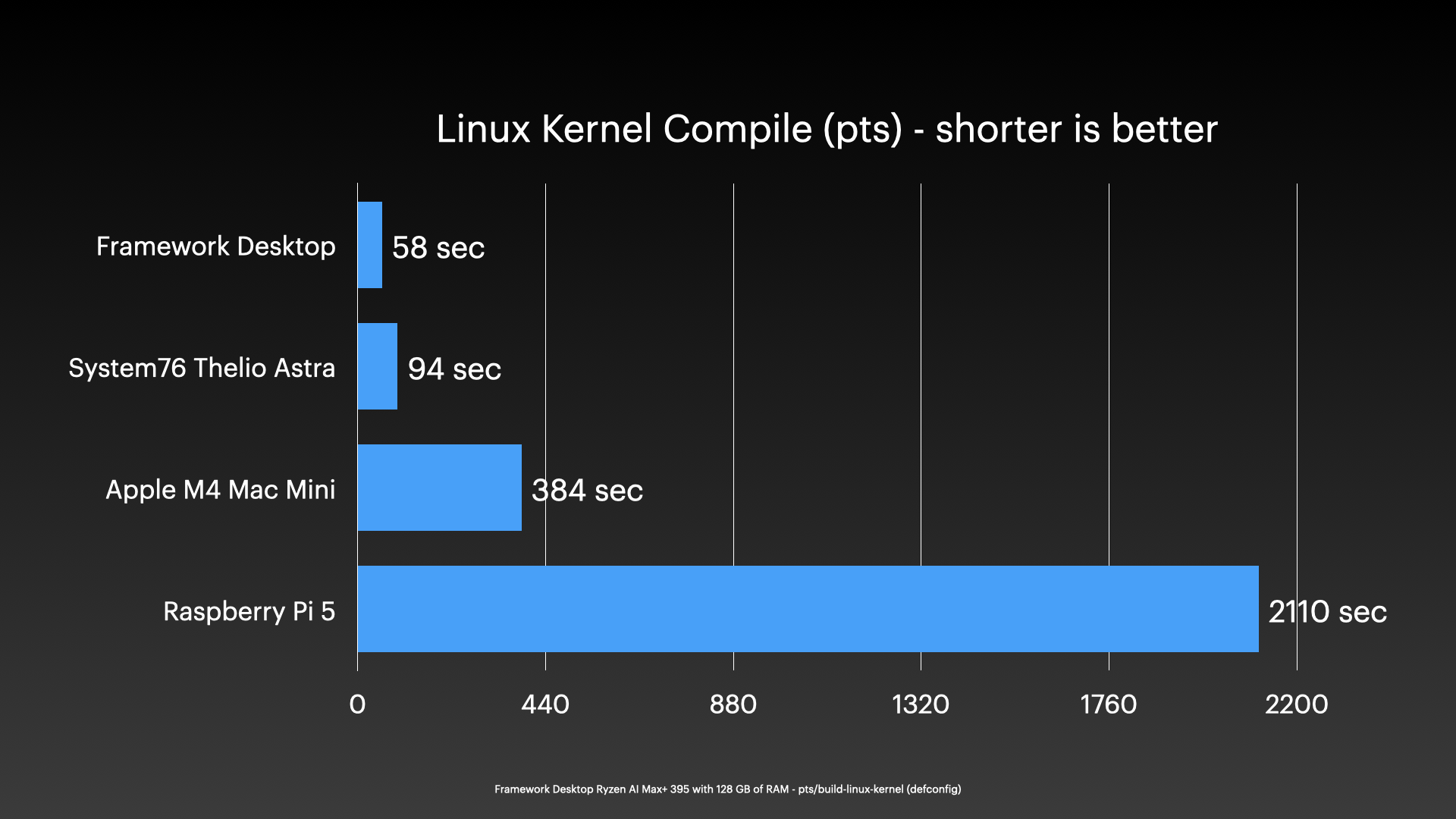
That’s impressive already, but put four of these together, and even without tweaking my HPL setup to utilize all the Ryzen AI Max+ chip features, I could achieve over 1 TFLOP of FP64 performance running my top500-benchmark:
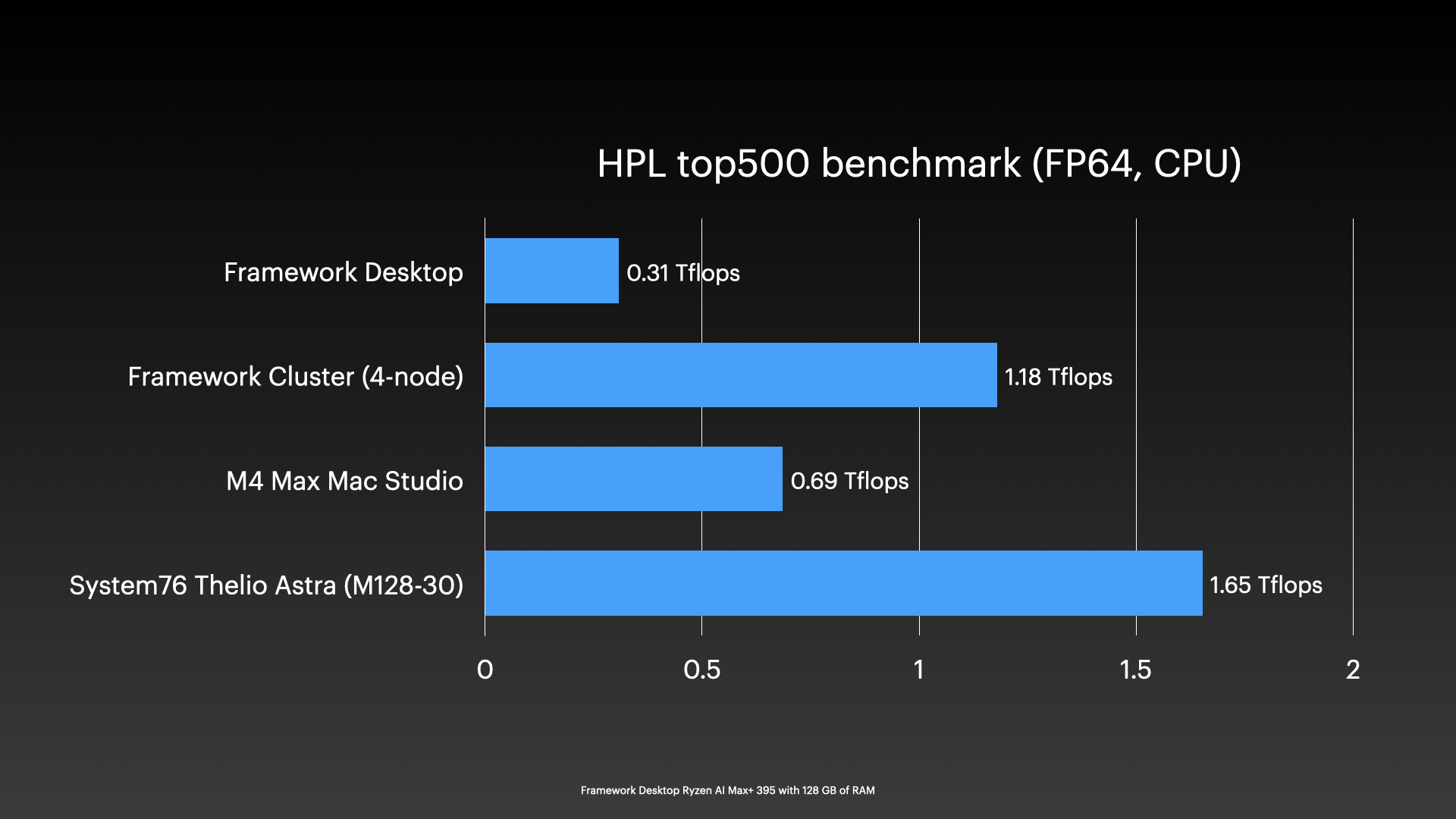
And CPU efficiency is good, but still a far cry from Apple M-series. It’s on par efficiency-wise, at least for FP64 compute, with a Pi 5 🙂
But most people who wanted to see more than one of these Framework systems put together were interested in clustered AI / LLM potential. So that’s where I’ll spend the rest of my time here.
AI Inference using the GPU
First of all, AMD’s support for their AI stuff is… okay. But not great. And that means I spent more time in my testing debugging ROCm driver and library issues than actually testing.
And some things I still haven’t gotten working, like the built in NPU. (In fact, some working NPU testing examples were finally released by AMD while I was working on this review. But not in time for me to fully test/validate them.)
Since I can’t test parts of the chip like the NPU, I can’t say anything useful about it, so as I always suggest: you’re buying the features that work and are tested today. Don’t ever buy something based on future promises, spec sheets, or ‘potential’.
Anyway, getting on with things, I had some initial trouble getting ROCm to work with Ollama on Fedora 42. Eventually I upgraded to Rawhide to get ROCm happy, and Ollama was also happy… but not as happy as just running llama.cpp directly.
On a single node, it was easy enough to use the CPU or the iGPU with either Vulkan or ROCm for inference. And it’s no slouch:
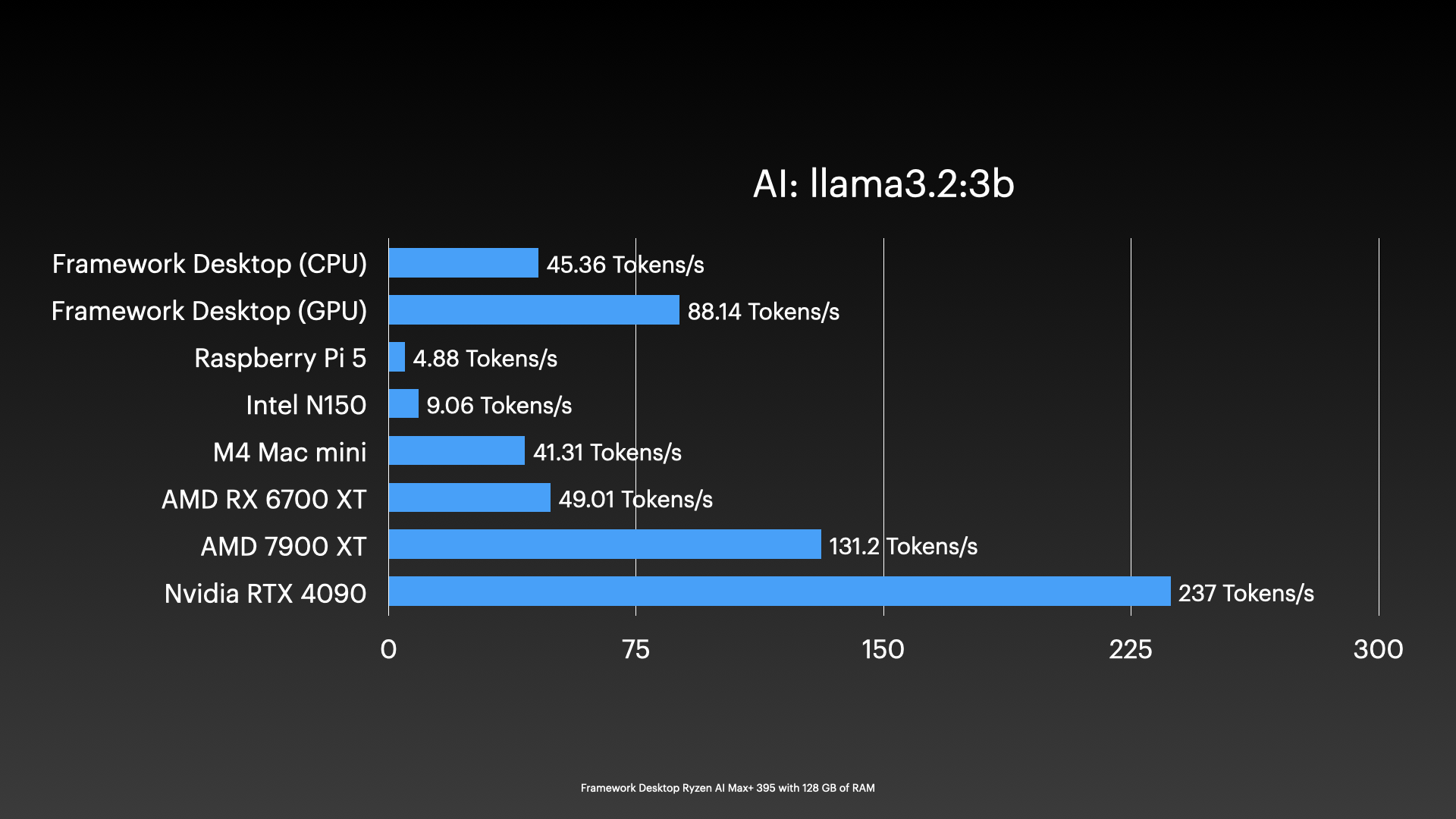
For an iGPU—and again, not using the NPU at all—I’m getting some pretty solid numbers. And efficiency (while not matching Apple) is also the best I’ve tested with any AMD consumer chips.
Again, visit the links earlier in this post for all the testing I’ve done (I tested a number of small, medium, and large AI models in both single node and cluster configurations).
For my final cluster testing, mostly to ensure I wasn’t running into any networking oddities, I stuck with the built-in NICs, and bought a NICGIGA 5 Gbps 8-port switch, since that’s the only way outside of a bunch of hot copper transceivers to get multiple 5 Gbps-capable RJ45 ports in one box.
Using my Beowulf AI Cluster project, I tested a variety of models on the cluster using Exo, llama.cpp RPC, and dllama, and here’s what I found:
- Exo seems unmaintained. So after bumping into some issues with Strix Halo support that have been unresolved for a while, I gave up on that.
- llama.cpp RPC runs great for smaller models, goes into ’round robin’ mode (that’s what I’m calling it) for larger models, and segfaults at some point for massive models like DeepSeek R1 Q4_K_M (see this issue).
- distributed-llama runs the models it supports (including Llama 3.1 405B) pretty well across a cluster… but Vulkan support was iffy at times, and inference would get wonky (usually resulting in one word repeating ad infinitum). Unfortunately only a few models are currently supported.
So there was no panacea.
llama.cpp’s RPC mode is definitely the most promising, but as an illustration of the round-robin problem with huge LLMs, I was monitoring the GPUs with nvtop during a llama-bench run, and you can watch as the main node would just pass processing from node to node:
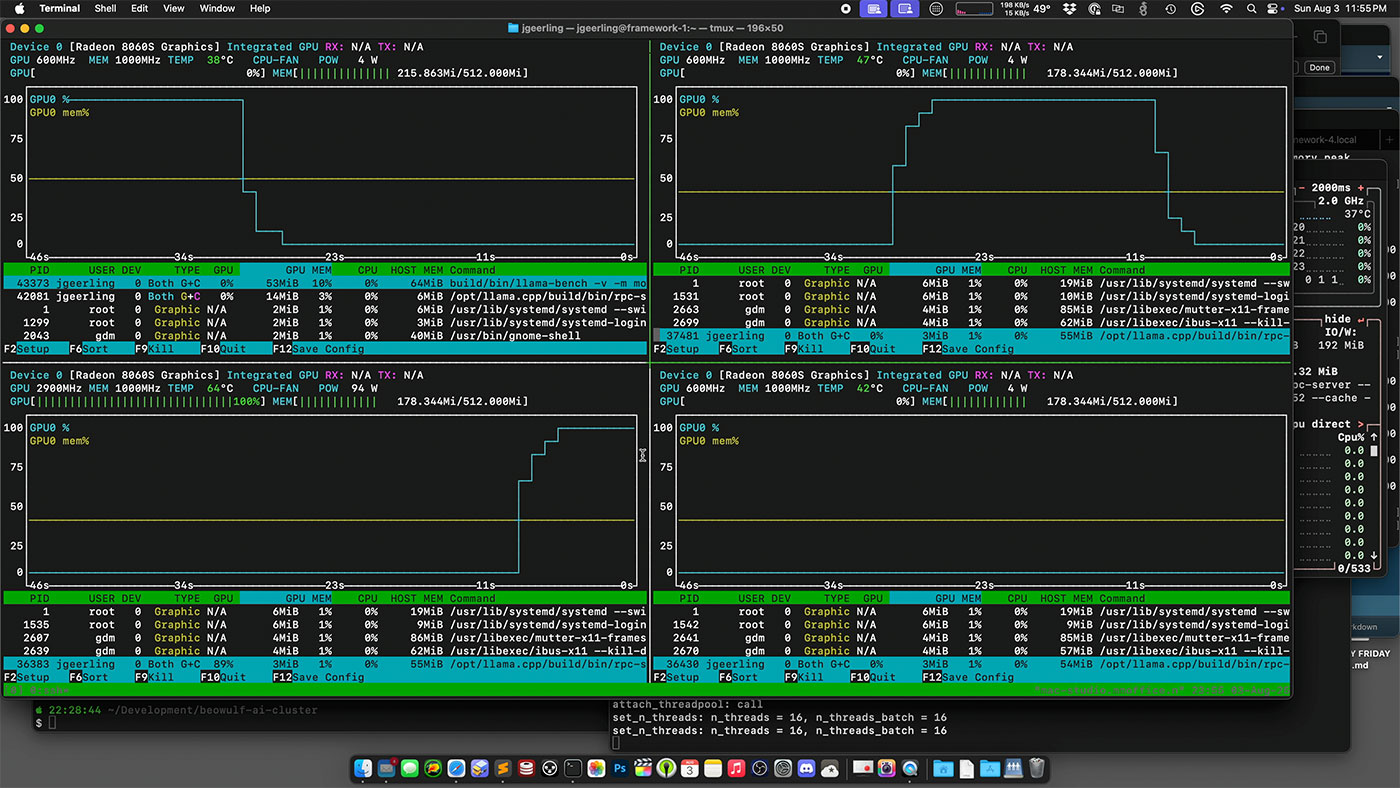
It would be great if llama.cpp could parallelize the workload, more like HPL does for FP64 math, but there are definitely some technical implementation hurdles! (The RPC functionality is marked experimental for that and many other reasons.)
Users on Reddit and Hacker News are always like “oh yeah, I could just buy some mini PCs and throw ’em together in an AI cluster! That’ll be awesome!”
But it’s just… not that easy.
Besides the network being like a billion times slower than memory, the tools for AI clustering aren’t ready for prime time.
Value
Getting back to the topic of value, not counting the DeskPi rack and trays, network switch, or cabling, the exact cluster configuration I tested will run you around $8,004.
How does it stack up against some other options for giant LLMs?
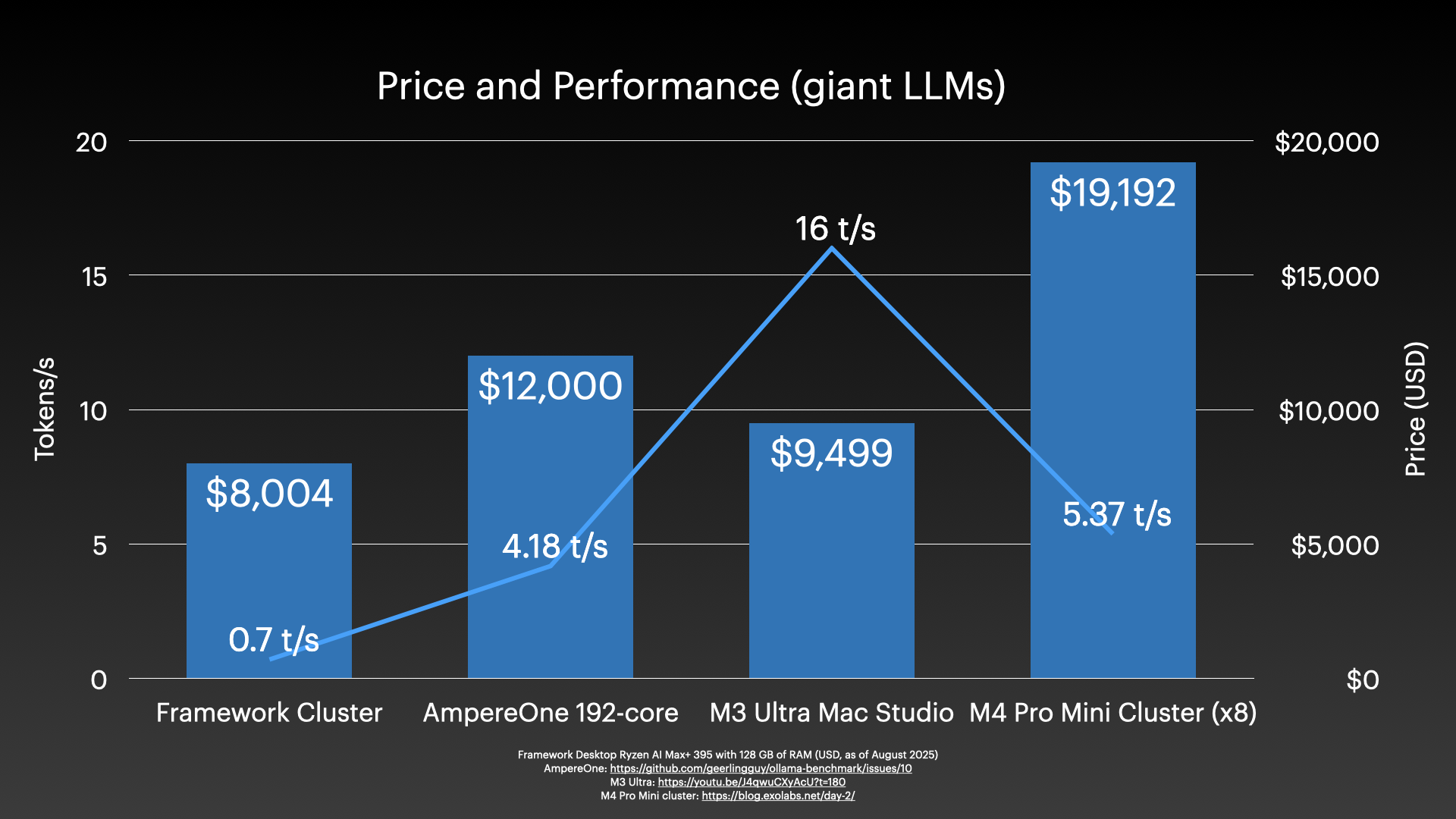
The AmpereOne server I tested last year gives me 4 tokens per second, just on the CPU, and it cost maybe around $12,000, I’m not sure of the exact price.
An M3 Ultra Mac Studio with 512 gigs of RAM will set you back just under $10,000, and it’s way faster, at 16 tokens per second.
And if you just want to waste money, buy a cluster of 8 M4 Pro Mac minis.
I should note the 0.7 t/s I quoted for the Framework Cluster in the above graph is for Llama 3.1 405B, versus other results for DeepSeek R1 671B (both at Q4), so it is not a perfect comparison—for that, I am still trying to get full DeepSeek R1 running.
I did get DeepSeek R1 Q2_K_M running, here are those results running across the full cluster with Vulkan:
| model | size | params | backend | ngl | threads | fa | mmap | test | t/s |
|---|---|---|---|---|---|---|---|---|---|
| deepseek2 671B Q2_K – Medium | 211.03 GiB | 671.03 B | Vulkan,RPC | 125 | 32 | 1 | 0 | pp512 | 26.86 ± 0.35 |
| deepseek2 671B Q2_K – Medium | 211.03 GiB | 671.03 B | Vulkan,RPC | 125 | 32 | 1 | 0 | tg128 | 8.25 ± 0.04 |
| deepseek2 671B Q2_K – Medium | 211.03 GiB | 671.03 B | Vulkan,RPC | 125 | 32 | 1 | 0 | pp512+tg128 | 17.22 ± 0.04 |
And since I know some people will ask, and I don’t want to keep it buried in the test result data on GitHub, here are the results for ChatGPT’s new ‘oss’ models, running on a single node:
gpt-oss-20b
| model | size | params | backend | ngl | threads | test | t/s |
|---|---|---|---|---|---|---|---|
| gpt-oss ?B F16 | 12.83 GiB | 20.91 B | Vulkan,RPC | 125 | 32 | pp512 | 564.23 ± 0.46 |
| gpt-oss ?B F16 | 12.83 GiB | 20.91 B | Vulkan,RPC | 125 | 32 | tg128 | 45.01 ± 0.05 |
| gpt-oss ?B F16 | 12.83 GiB | 20.91 B | Vulkan,RPC | 125 | 32 | pp512+tg128 | 167.77 ± 0.09 |
gpt-oss-120b
| model | size | params | backend | ngl | threads | test | t/s |
|---|---|---|---|---|---|---|---|
| gpt-oss ?B F16 | 60.87 GiB | 116.83 B | Vulkan,RPC | 125 | 32 | pp512 | 216.93 ± 0.74 |
| gpt-oss ?B F16 | 60.87 GiB | 116.83 B | Vulkan,RPC | 125 | 32 | tg128 | 33.12 ± 0.00 |
| gpt-oss ?B F16 | 60.87 GiB | 116.83 B | Vulkan,RPC | 125 | 32 | pp512+tg128 | 101.13 ± 0.13 |
Running across the cluster (instead of on just one node), tg128 inference was down to 24 tokens/s.
Inference with the current state-of-the-art for open source AI clustering tools is always going to be slower across multiple machines, than if you can just run the model on one machine with tons of RAM.
Thus, my main takeaway: try to scale vertically as much as you can. Clustering makes things hard, and with AI, doubly so.
Maybe at some point open source AI clustering tools will get as good as other HPC tools, but right now, if you want better cluster performance, you need to get specialized hardware and high speed interconnects, and spend a lot of time optimizing things.
Conclusion
All that to say, I think I agree with Nirav: AI clustering is interesting, but it’s far from becoming mainstream.
The Framework Desktop makes for a great little Mini ITX system, and you can even cluster it in a mini rack. But don’t expect it to start training your own models to solve world hunger—at least not today.

{kind=link}